
在國際范圍內,對硅半導體的資料科學,制作工藝,有才能也有志愿繼續的廠商可能只留下了Intel,Samsung,TSMC與Global Foundries。在近期或許在不久的將來,或許我國為了完結國際工廠的巨大轉型,將接過半導體生產制作的旗號,使其愈加廉價,使其愈加缺少必要的盈余以支撐整個產業鏈的繼續開展,維系也在完結這個職業。我繼續悲觀地維持在幾年前的判斷[3],根據硅的半導體工業不可或缺,也不再重要。談核算
緣起于上世紀四十年代的馮諾依曼系統正在等待著最終一根稻草。至今處理器的規劃者再也無法依照自身的理念決議自己的規劃方向,當這些處理器的規劃者不知道做什么適宜,而回身專心于Cache、內存與I/O通路時,根據馮諾依曼系統的傳統處理器現實上現已完畢。把握用戶場景與運用的廠商現在是處理器真實的規劃主導者。定制化時代不再是多年之前的預判[4],而是已然降臨,并操縱著處理器規劃的方向。
硅半導體與傳統處理器的停滯不前,不會完畢人類關于硅的依靠,在短期內尚無任何資料能夠完全代替硅。運用關于硅的需求仍然清晰。在一分鐘內,Youtube將至少接納長達100個小時的視頻文件[5];在Facebook上,每天有40億次視頻點擊播映[6]。這些運用需求將經過網絡,抵達各類效勞器,并從存儲器中獲取或許寫入數據,進行著各類數據的處理。在核算、網絡與存儲這些根底架構中,硅半導體仍然占有主導地位。
奇特的半導體硅改變了人類前史的開展軌道,也簡直走到了盡頭。近半個世紀以來,硅一向有互補品,如砷化鎵GaAs與氮化鎵GaN,這些在大功率與高頻范疇已有著嚴重運用的半導體資料無法代替硅,根據二硫化鉬MoS2和碳納米管CNT (Carbon Nanotube)的晶體管乃至能夠將Gate Length做到1nm[7],可是仍然處于實驗室階段,用其代替硅只是停留在論文的紙面之上。至今硅工業的天花板制約了整個IT根底設施職業行進的腳步。
在核算范疇,被軟銀收買的ARM現已難以對x86處理器帶來繼續的壓力。在手機處理器上取得了長足進步的蘋果、高通、三星與華為,在近期難以在效勞器市場上對Intel帶來實質性的應戰。許多ARM效勞器在SPECInt的測驗中聲稱已逐步接近了x86處理器,卻在有意無意的疏忽著一個清楚明了的現實,這一代的效勞器,乃至是手機處理器,都不應該繼續關注SPECInt與SPECfp這類單純比拼核算功能的基準測驗。
現在處理器的規劃中心現已轉向I/O與Memory Hierarchy通路的建設。在Intel的Broadwell-E處理器的Die Map[8]中,10個處理器微架構(Core)合在一起所占的份額現已不算太大,Memory Hierarchy與I/O占有了大多數的Die資源。
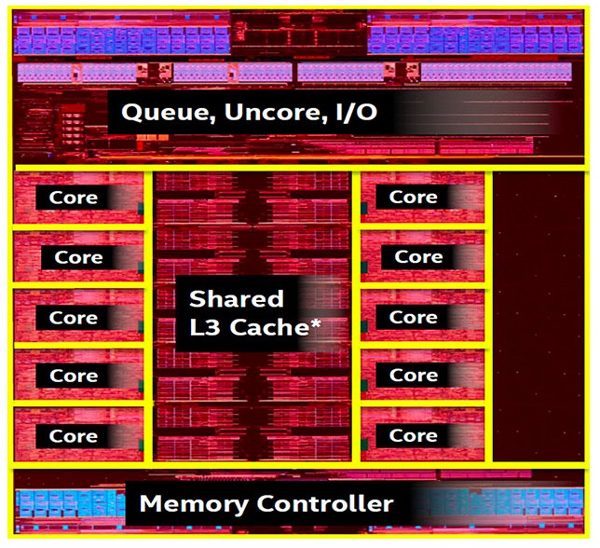
圖12 Intel的Broadwell-E處理器的Die Map[8]
在一個處理器微架構中,運算單元所占的份額簡直能夠疏忽不計,在處理器微架構中,仍然是品種繁復,各類數據緩沖占有著主導方位。現實上,除了模仿器材以及與模仿器材強相關的芯片外,在多數芯片Die Map中,緩沖都占有著要害方位。迄今為止,核算范疇的多數運用對處理器的運用都是訪存密集型。
處理器的規劃初衷本是為核算效勞,可是在今天的許多運用場景中,處理器所承當更多的使命是經過各類I/O設備獲取數據;這些數據在穿越Memory Hierarchy后抵達CPU的中心部件;CPU中心部件在準確核算著心跳的過程中,盡可能地快速處理這些數據,然后將其再次轉發至遠方。和密集核算相關的使命,現現已過各類硬件加快引擎,GPU或許專用ASIC完成。
咱們無法直面一個簡略而令人懊喪的現實,在處理器運轉著的各類協議棧的代碼組成中,用于完成快速路徑的代碼可能不超越1%;99%以上的用于反常處理的代碼,能夠在超越99.9%以上的時間段內安然入眠,其存在只為等待著可能的反常呈現。
不是由于這些數不勝數的反常需求處理,或許咱們這個國際現已不再需求通用處理器了。從純核算的角度上剖析,各類硬件加快引擎,GPU、FPGA或許專用ASIC,遠勝今天的處理器,可是這些加快引擎在面臨不計其數種反常時力不從心。在移動互聯網廠商的數據中心中,處理器存在的最首要意圖是對各類數據流進行剖析、拼裝、打包后發往下一站。
在這些運用場景中,處理器存在的首要原因仍然不是其高效的報文轉發才能,而是能夠應對在報文處理過程中呈現的各類反常。在數據中心中,處理器存在的首要效果是能夠相對高效地處理數據報文,一起還能對各類反常進行查漏補缺。不僅在核算范疇,在IT根底設施的網絡與存儲范疇,通用處理器的運用方法仍然如此。
能夠對通用處理器帶來應戰的GPU,遠景沒有想象中樂觀。從規劃戰略上看,GPU與通用處理器的最大差異在于對反常的處理。GPU專心極致核算,盡最大的可能提高TLP (Thread-Level Parallelism),而疏忽反常處理;通用處理器需求考慮反常狀態的處理,以追求更大的適用性。
在不同規劃戰略的引導下,GPU走出了一條與通用處理器懸殊的路途。Nvidia的Pascal GP100由最多可達6個的一組GPC (Graphics Processing Clusters)構建;這些GPC共享同一個4096 KB的L2 Cache;經過8個512位的Memory Controller對外交流數據;運用高速的NVLink接口與其他GP100互聯;最終經過PCIe 3.0總線與通用處理器進行銜接[9]。
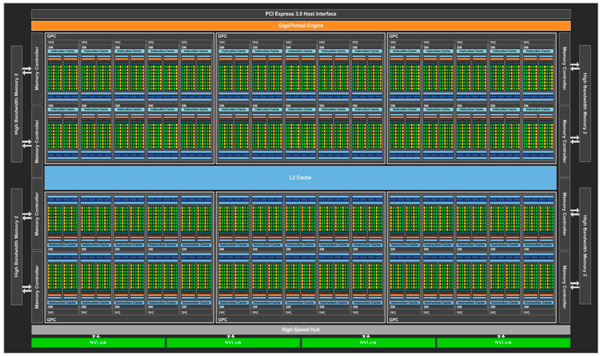
圖13 Nvidia Pascal GP100 GPU組成結構[9]
在每一個GPC中,最多能夠包容5個TPC (Texture Processing Clusters);每個TPC中集成兩個SM (Streaming Multiprocessors);每一個SM包括64個CUDA和4個TU (Texture Unit)。其間最基本的CUDA中心和TU數目別離可達3840與個240個。GPU的Die Size可達610mm2,所能包容的晶體管數目可達153億個[9]。
GPU與通用處理器,是規劃者在面臨有限的Die Size資源,做出的不同挑選,以適用于不同的運用場景。由數目繁復的運算單元所組成的GPU,其組成結構不比通用處理器雜亂,反而更為簡略。可是這無法解釋,Intel能夠做出更為雜亂的通用處理器,卻在高端GPU范疇上重復折戟沉沙;也無法解釋,效勞器級處理器的規劃難度超越手機處理器,Intel仍然百戰百勝。
通用處理器需求處理各類已知與不知道的反常,在進行核算的一起,不斷地處理各類分支跳轉語句;隨時預備應對各類中止事情;與此一起需求具有大規劃的數據吞吐才能;也因此通用處理器需求一個規劃龐大的通用操作系統。至今,核算已是通用處理器中的一個微小組成模塊,通用處理器中最大的模塊,是各類Cache和與其緊密聯系在一起的Memory Hierarchy。
GPU聚焦的核算國際相對單純;所處理的數據規整;數據間簡直沒有太多的依靠;不需求辦理外部設備,不需求處理各類中止與反常,也不需求一個操作系統。從GPU的開展前史上,能夠發現,GPU所處理的圖畫數據并不具有十分強的Locality特性。在GPU中,Cache存在的首要效果不是為了保存需求重復運用的數據,而是為了補償GPU內部運算部件與外部DRAM之間的拜訪推遲,然后沒有如通用處理器那樣的,雜亂程度令人拍案叫絕的Cache Hierarchy結構。
在GPU中,存在與通用處理器相似的流水線,Nvidia的GP100中的基本組成模塊SM,自身就是也是一個流水線,這個流水線也被稱為Graphics Pipeline,在不考慮光柵化處理的場景下,Graphics Pipeline也被稱為Rendering Pipeline。
注:文章內容和圖片均來源于網絡,只起到信息的傳遞,不是用于商業,如有侵權請聯系刪除!



